O esquema que se irá seguir de correcçăo de erros de códigos lineares gerais recorre aos síndromes. Para tal, é preciso calcular o número de erros do código linear ŕ custa de, por exemplo, uma matriz geradora ou de uma matriz de paridade. Listam-se entăo os síndromes dos líderes de cada classe. Recebido um vector, este é corrigível se o seu síndrome igualar um único síndrome de um líderes, líder esse que é subtraído ao vector recebido por forma a se efectuar a correcçăo.
Suponha que ![]() é matriz geradora de um código
é matriz geradora de um código ![]() , onde
, onde
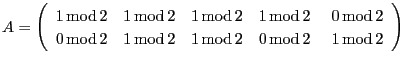
Esta matriz tem característica 2:
>> rank(A)
2
Como o código é linear, a distância mínima do código é igual ao menor peso de Hamming das palavras-código năo nulas. Ou seja,
Para se aplicar o esquema de correcçăo de erros, é ainda necessário calcular a matriz de paridade. Ou seja, uma matriz com característica 3 tal que ![]() . Ou ainda, uma matriz cujas colunas da transposta formem uma base do espaço nulo de
. Ou ainda, uma matriz cujas colunas da transposta formem uma base do espaço nulo de ![]() .
.
>> nullspace(A)
-- +- -+ +- -+ +- -+ --
| | 0 mod 2 | | 1 mod 2 | | 1 mod 2 | |
| | | | | | | |
| | 1 mod 2 | | 0 mod 2 | | 1 mod 2 | |
| | | | | | | |
| | 1 mod 2 |, | 0 mod 2 |, | 0 mod 2 | |
| | | | | | | |
| | 0 mod 2 | | 1 mod 2 | | 0 mod 2 | |
| | | | | | | |
| | 0 mod 2 | | 0 mod 2 | | 1 mod 2 | |
-- +- -+ +- -+ +- -+ --
Neste caso,
>> H:=concatMatrix(nullspace(A)[1],nullspace(A)[2],nullspace(A)[3])
+- -+
| 0 mod 2, 1 mod 2, 1 mod 2 |
| |
| 1 mod 2, 0 mod 2, 1 mod 2 |
| |
| 1 mod 2, 0 mod 2, 0 mod 2 |
| |
| 0 mod 2, 1 mod 2, 0 mod 2 |
| |
| 0 mod 2, 0 mod 2, 1 mod 2 |
+- -+
Em casos mais complexos, será preciso criar um ciclo de forma a se construir a concatenaçăo iterativamente. Repare que a matriz de paridade é a transposta da matriz apresentada em cima. Portanto,
>> H:=transpose(H)
+- -+
| 0 mod 2, 1 mod 2, 1 mod 2, 0 mod 2, 0 mod 2 |
| |
| 1 mod 2, 0 mod 2, 0 mod 2, 1 mod 2, 0 mod 2 |
| |
| 1 mod 2, 1 mod 2, 0 mod 2, 0 mod 2, 1 mod 2 |
+- -+
Os líderes săo, visto o código corrigir 1 erro, as linhas da matriz identidade ![]() , e portanto os síndromes dos líderes năo săo mais que as colunas de
, e portanto os síndromes dos líderes năo săo mais que as colunas de ![]() .
.
Suponha que se recebeu por uma canal simétrico binário com ruído o vector
Calcula-se o síndrome
>> H*transpose(r)
+- -+
| 0 mod 2 |
| |
| 0 mod 2 |
| |
| 1 mod 2 |
+- -+
Como o síndrome năo é nulo, segue que
>> I5:=M2(matrix::identity(5)):
>> c:=r+row(I5,5)
+- -+
| 1 mod 2, 0 mod 2, 0 mod 2, 1 mod 2, 1 mod 2 |
+- -+